ModelAdmin のオプション
ModelAdmin はとてもフレキシブルなクラスです。このクラスには、 admin イ
ンタフェースをカスタマイズするためのオプションがいくつもあります。オプショ
ンは、全て、 ModelAdmin のサブクラスで以下のように指定します:
class AuthorAdmin(admin.ModelAdmin):
date_hierarchy = 'pub_date'
-
ModelAdmin.date_hierarchy
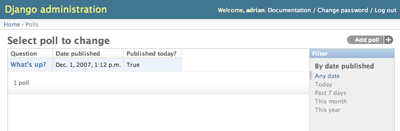
date_hierarchy をモデルの DateField や DateTimeField に指定する
と、変更リストのページに、指定フィールドの日付を使って日付ベースで絞り込み
できるナビゲーションが組み込まれます。
例:
date_hierarchy = 'pub_date'
-
ModelAdmin.form
デフォルトの設定では、モデルに対して ModelForm が動的に生成され、追加/
変更ページでフォームを生成するときに使われます。 form を独自の
ModelForm と置き換えれば、追加/変更ページのふるまいを変更できます。
詳しくは、 admin にカスタムのバリデーションを追加する を参照してください。
-
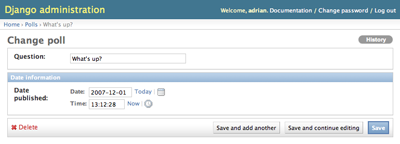
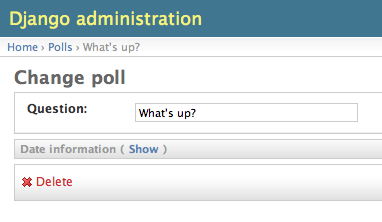
ModelAdmin.fieldsets
admin の「追加 (add)」および「変更 (change)」ページのレイアウトを制御するに
は、 fieldsets を使います。
fieldsets は 2 要素のタプルのリストです。各タプルは admin フォームペー
ジ上の <fieldset> を表します (<fieldset> はいわばフォームの「セクショ
ン」です)。
フィールドセットは (name, field_options) の形式をとります。 name
はフィールドセットの名前を表す文字列で、 field_options はフィールドセッ
ト内で表示したいフィールドの情報を入れた辞書です。この情報の中に、表示した
いフィールドのリストも指定します。
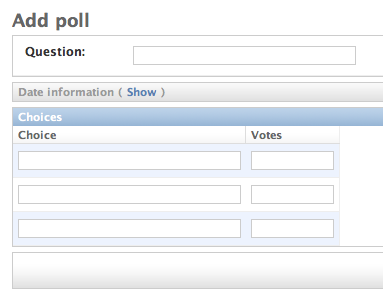
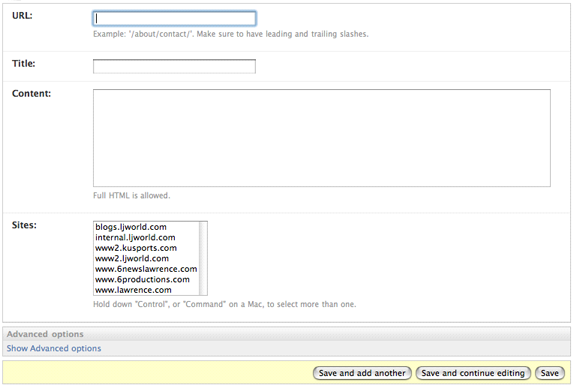
django.contrib.flatpages.FlatPage モデルから抜き出した例を示します:
class FlatPageAdmin(admin.ModelAdmin):
fieldsets = (
(None, {
'fields': ('url', 'title', 'content', 'sites')
}),
('Advanced options', {
'classes': ('collapse',),
'fields': ('enable_comments', 'registration_required', 'template_name')
}),
)
このフィールドセットによって、 admin のページは以下のようになります:
fieldsets を指定しない場合、 Django は AutoField でなく、かつ
editable=True であるようなフィールドを、モデルに定義した順番に個別のフィー
ルドセットとして表示します。
field_options 辞書には以下のようなキーを指定できます:
-
ModelAdmin.fields
レイアウトを気にせず、単にモデルの一部のフィールドだけをフォームに表示した
いだけの場合に、 fieldsets の代わりに使ってください。例えば、
django.contrib.flatpages.FlatPage モデルの admin フォームの簡単なバージョ
ンを以下のように定義できます:
class FlatPageAdmin(admin.ModelAdmin):
fields = ('url', 'title', 'content')
上の例では、 ‘url’, ‘title’, ‘content’ フィールドだけが順番にフォームに表示
されます。
Note
この fields オプションと fieldsets オプションの中の fields
キーとを混同しないでくださいね。
-
ModelAdmin.exclude
この属性にフィールドの名前のリストを指定すると、指定したフィールドがフォー
ムから除去されます。
例えば、以下のようなモデルがあったとします:
class Author(models.Model):
name = models.CharField(max_length=100)
title = models.CharField(max_length=3)
birth_date = models.DateField(blank=True, null=True)
name と title フィールドだけを含む Author モデルのフォームを
表示したければ、 fields や exclude を使って、それぞれ以下のように
定義できます:
class AuthorAdmin(admin.ModelAdmin):
fields = ('name', 'title')
class AuthorAdmin(admin.ModelAdmin):
exclude = ('birth_date',)
Author モデルは 3 つのフィールド name, title, birth_date
しか持たないので、上の 2 つの例は全く同じフィールドを含むフォームを生成しま
す。
-
ModelAdmin.filter_horizontal
ユーザビリティが紙一重の <select multiple> の代わりに、気の利いた控えめ
な Javascript の「フィルタ」インタフェースを使います。フィルタインタフェー
スを横並びにして表示させたいフィールドのリストを指定してください。フィルタ
インタフェースを縦並びにしたい場合は filter_vertical を使ってください。
-
ModelAdmin.filter_vertical
filter_horizontal とほぼ同じですが、フィルタインタフェースを縦並びで表
示します。
-
ModelAdmin.list_display
admin の変更リストページに表示するフィールドを制御するには list_display
を使います。
使い方:
list_display = ('first_name', 'last_name')
list_display を指定しなければ、 admin サイトは各オブジェクトの
__unicode__() 表現を表示するカラムを一つだけ表示します。
list_display には 4 通りの設定方法があります:
モデルのフィールド名:
class PersonAdmin(admin.ModelAdmin):
list_display = ('first_name', 'last_name')
モデルインスタンスを引数にとる呼び出し可能オブジェクト:
def upper_case_name(obj):
return "%s %s" % (obj.first_name, obj.last_name).upper()
upper_case_name.short_description = 'Name'
class PersonAdmin(admin.ModelAdmin):
list_display = (upper_case_name,)
ModelAdmin の属性名を表す文字列。呼び出し可能オブジェクトと同じよ
うに動作します:
class PersonAdmin(admin.ModelAdmin):
list_display = ('upper_case_name',)
def upper_case_name(self, obj):
return "%s %s" % (obj.first_name, obj.last_name).upper()
upper_case_name.short_description = 'Name'
モデルの属性名を表す文字列。ただし、 self はモデルインスタンスを
表します:
class Person(models.Model):
name = models.CharField(max_length=50)
birthday = models.DateField()
def decade_born_in(self):
return self.birthday.strftime('%Y')[:3] + "0's"
decade_born_in.short_description = 'Birth decade'
class PersonAdmin(admin.ModelAdmin):
list_display = ('name', 'decade_born_in')
list_display にはいくつか特殊なケースがあります:
フィールドが ForeignKey の場合、関連づけられているオブジェクトの
__unicode__() を表示します。
ManyToManyField フィールドの表示は、テーブルの各行に対して個別に
SQL 文を実行することになってしまうのでサポートしていません。どうして
も表示させたいなら、カスタムメソッドをモデルに実装して、メソッドの名
前を list_display に追加してください (list_display へのカスタ
ムメソッドの追加については、後で詳しく説明しています)。
フィールドが BooleanField や NullBooleanField の場合、
True や False の代りに “オン” や “オフ” を示すアイコンを表示
します。
モデルや ModelAdmin のメソッド、呼び出し可能オブジェクトの名前を
指定した場合、 Django はデフォルトでメソッドの出力を HTML エスケープ
します。メソッドの出力をエスケープしたくない場合には、メソッドの
allow_tags 属性の値を True にしてください。
以下に例を示します:
class Person(models.Model):
first_name = models.CharField(max_length=50)
last_name = models.CharField(max_length=50)
color_code = models.CharField(max_length=6)
def colored_name(self):
return '<span style="color: #%s;">%s %s</span>' % (self.color_code, self.first_name, self.last_name)
colored_name.allow_tags = True
class PersonAdmin(admin.ModelAdmin):
list_display = ('first_name', 'last_name', 'colored_name')
True か False を返すようなモデルの ModelAdmin のメソッド、
呼び出し可能オブジェクトの名前を指定した返す場合、メソッドの
boolean 属性を True に設定しておくと、Django は「オン」や「オ
フ」のアイコンを表示します。
以下に例を示します:
class Person(models.Model):
first_name = models.CharField(max_length=50)
birthday = models.DateField()
def born_in_fifties(self):
return self.birthday.strftime('%Y')[:3] == '195'
born_in_fifties.boolean = True
class PersonAdmin(admin.ModelAdmin):
list_display = ('name', 'born_in_fifties')
__str__() および __unicode__() メソッドは他のモデルメソッドと
同じように list_display に入れられるので、以下のように書いても全
く問題ありません:
list_display = ('__unicode__', 'some_other_field')
通常、 list_display の要素のうち、実際のデータベースのフィールド
に対応していないものは、変更リストページで並び順を変えるときのカラム
には使えません。 Django はソートをすべてデータベースレベルで行うから
です。
ただし、 list_display のいずれかの要素が実際にデータベース上のあ
るフィールドを指している場合、 admin_order_field という属性を使っ
て、 Django にそのことを教えられます。
例を示しましょう:
class Person(models.Model):
first_name = models.CharField(max_length=50)
color_code = models.CharField(max_length=6)
def colored_first_name(self):
return '<span style="color: #%s;">%s</span>' % (self.color_code, self.first_name)
colored_first_name.allow_tags = True
colored_first_name.admin_order_field = 'first_name'
class PersonAdmin(admin.ModelAdmin):
list_display = ('first_name', 'colored_first_name')
この例では、 Django は Admin 上で colored_first_name を並べ変える
際に first_name フィールドを使います。
-
ModelAdmin.list_display_links
list_display_links を設定すると、 list_display のどのフィールドを
オブジェクトの「変更」ページにリンクするかを制御できます。
デフォルトでは、変更リストページはオブジェクトの変更ページ中の第一カラム、
すなわち list_display の先頭に指定したフィールドにリンクを張ります。
list_display_links を使うと、リンク先のカラムを変更できます。
list_display_links には、フィールド名のリストまたはタプルを
(list_display と同じ形式で) 指定します。
list_display_links に指定するフィールド名は、一つでも複数でも構いません。
フィールド名が list_display に列挙されている限り、 Django はどんなに多
くの (あるいはどんなにわずかな) フィールドがリンクされていても問題にしませ
ん。必要なのは、 list_display_links を使うには list_display を定義
しておかねばならない、ということだけです。
以下の例では、 first_name および last_name フィールドが変更リス
トページにリンクされます:
class PersonAdmin(admin.ModelAdmin):
list_display = ('first_name', 'last_name', 'birthday')
list_display_links = ('first_name', 'last_name')
-
ModelAdmin.list_editable
Set list_editable to a list of field names on the model which will allow
editing on the change list page. That is, fields listed in list_editable
will be displayed as form widgets on the change list page, allowing users to
edit and save multiple rows at once.
Note
list_editable interacts with a couple of other options in particular
ways; you should note the following rules:
- Any field in
list_editable must also be in list_display. You
can’t edit a field that’s not displayed!
- The same field can’t be listed in both
list_editable and
list_display_links – a field can’t be both a form and a link.
You’ll get a validation error if either of these rules are broken.
-
ModelAdmin.list_filter
admin の変更リストページの右側のサイドバーにあるフィルタを有効にするには、
list_filter を設定します。この値はフィールド名のリストにします。
各フィールド名は BooleanField, CharField, DateField,
DateTimeField, IntegerField, ForeignKey のいずれかでなければ
なりません。
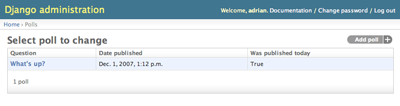
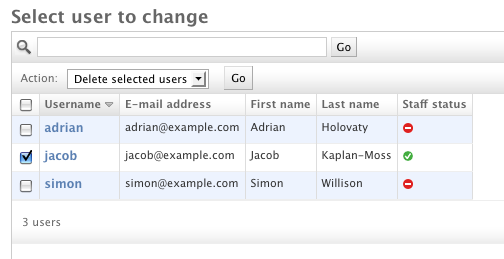
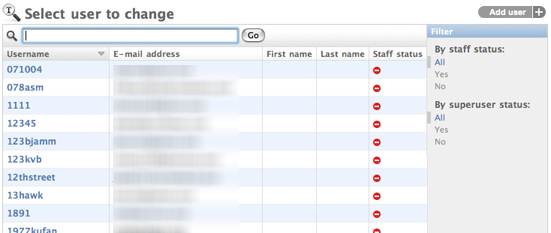
以下の例は django.contrib.auth.models.User モデルからとったもので、
list_display と list_filter の仕組みを示しています:
class UserAdmin(admin.ModelAdmin):
list_display = ('username', 'email', 'first_name', 'last_name', 'is_staff')
list_filter = ('is_staff', 'is_superuser')
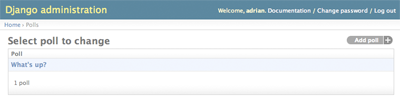
上のコードによって、 admin の変更リストは以下のようになります:
(この例では、後述の search_fields も定義しています。)
-
ModelAdmin.list_per_page
admin 変更リストをページ分割 (paginate) で表示するときに、各ページに何個の
アイテムを表示するかを決めます。デフォルト値は 100 です。
-
ModelAdmin.list_select_related
list_select_related を設定すると、 admin の変更リストページに表示するオ
ブジェクトリストを取得する際に select_related() を使うよう Django に指
示できます。これにより、データベースクエリの発行数を抑えられます。
値は True または False にします。デフォルトは False です。
list_display のいずれかのフィールドが ForeignKey の場合、 Django は
この設定に関わらず select_related() を使います。
select_related() の詳細は
select_related() のドキュメント を参照してください。
-
ModelAdmin.inlines
後述の InlineModelAdmin を参照してください。
-
ModelAdmin.ordering
ordering を設定すると、 admin の変更リストにおける整列順を指定できます。
値はタプルからなるリストで、モデルの ordering パラメタと同じ形式で指定
します。
この値を指定しない場合、 Django はモデルのデフォルトの整列順を使います。
Note
Django はリストやタプルの最初の要素だけを考慮して、後の要素は無視します。
-
ModelAdmin.prepopulated_fields
フィールドの値を別のフィールドの値からセットさせたい場合は、以下のように、
prepopulated_fields にフィールド名を対応付けた辞書を設定してください:
class ArticleAdmin(admin.ModelAdmin):
prepopulated_fields = {"slug": ("title",)}
prepopulated_fields をセットすると、フィールドに小さな JavaScript のア
クションが設定され、引数に指定したフィールドから値を自動的に取り込みます。
prepopulated_fields は、主に他の複数のフィールドから SlugField フィー
ルドの値を生成するときに使います。値は、まず各ソースフィールドの値を結合し
て、その結果が有効なスラグになるよう変換 (スペースをダッシュに置換するなど)
して生成します。
DateTimeField, ForeignKey および ManyToManyField は
prepopulated_fields に指定できません。
-
ModelAdmin.radio_fields
デフォルトでは、Django の admin は ForeignKey のフィールドや
choices の設定されたフィールドに対してセレクタボックス (<select>) イン
タフェースを使います。 radio_fields にフィールド名を指定しておくと、
Django はセレクタボックスの代りにラジオボタンのインタフェースを使います。
例えば、 group が Person モデル上の ForeignKey フィールド
であれば、以下のように書けます:
class PersonAdmin(admin.ModelAdmin):
radio_fields = {"group": admin.VERTICAL}
ラジオボタンの並び方を指定するシンボル、 HORIZONTAL または VERTICAL
は django.contrib.admin モジュールにあります。
ForeignKey や choices パラメタのセットされたフィールド以外に
radio_fields を使ってはなりません。
-
ModelAdmin.raw_id_fields
デフォルトでは、Django の admin サイトは ForeignKey フィールドに対して
セレクタボックス (<select>) インタフェースを使います。しかし、時にはリレー
ション先の全てのオブジェクトの入ったセレクタボックスが生成され、ドロップダ
ウン表示されるのを避けたい場合もあります。
raw_id_fields には、ウィジェットを Input に変更したいフィールドのリ
ストを指定します。 ForeignKey または ManyToManyField を指定できます:
class ArticleAdmin(admin.ModelAdmin):
raw_id_fields = ("newspaper",)
-
ModelAdmin.save_as
save_as を指定すると、 admin の編集フォームで「別名で保存 (save as)」機
能を使えるようになります。
通常、編集フォームには三つの保存オプション、すなわち「保存 (Save)」、「保存
して編集を続ける (Save and continue editing)」、「保存してもう一つ追加
(Save and add another)」があります。 save_as を True にすると「保存
してもう一つ追加」は「別名で保存 (Save as)」に置き換わります。
「別名で保存」は、現在のオブジェクトをそのまま保存するのではなく、(新たな
ID を持った) 別のオブジェクトとして保存することです。
デフォルトでは、 save_as は False に設定されています。
-
ModelAdmin.save_on_top
save_on_top を指定すると、 admin の変更フォームの最上部に保存ボタンを追
加できます。
通常、保存ボタンはフォームの最下部だけに表示されます。 save_on_top を指
定すると、ボタンは最下部だけでなく最上部にも表示されます。
デフォルトでは、 save_on_top は False です。
-
ModelAdmin.search_fields
search_fields を指定すると、 admin の変更リストページで検索ボックスを使
えるようになります。この値は、ユーザが検索クエリをテキストボックスに入力し
たときに検索の対象に含めるフィールド名のリストです。
フィールドは CharField や TextField のような何らかのテキストフィー
ルドでなければなりません。 DB API の「リレーションを追跡する」表記を使えば、
ForeignKey を介したフィールドの指定も行えます:
search_fields = ['foreign_key__related_fieldname']
admin の検索ボックスで検索を実行すると、 Django は検索クエリを単語に分解し
て、各単語を含むような全てのオブジェクトを返します。検索は大小文字を区別せ
ず、 search_fields に指定したフィールドのうち少なくとも一つに単語が入っ
ていればヒットします。例えば、 search_fields が
['first_name', 'last_name'] に設定されている場合、ユーザが
john lennon を検索すると、 Django は以下のような WHERE 節を持った
SQL と等価な検索を実行します:
WHERE (first_name ILIKE '%john%' OR last_name ILIKE '%john%')
AND (first_name ILIKE '%lennon%' OR last_name ILIKE '%lennon%')
より高速な、あるいはより制約の厳しい検索を行うには、フィールド名の前に以下
のような演算子を置きます:
^フィールドの先頭にマッチします。例えば、 search_fields を
['^first_name', '^last_name'] にして、ユーザが john lennon を検
索した場合、Django は以下のような WHERE 節の SQL に等価な検索を実行
します:
WHERE (first_name ILIKE 'john%' OR last_name ILIKE 'john%')
AND (first_name ILIKE 'lennon%' OR last_name ILIKE 'lennon%')
このクエリを使うと、データベースはカラムの先頭部分だけをチェックすれば
よく、カラム中のデータ全体を調べなくてもよくなるため、通常の
'%john%' クエリよりも効率的に検索を実行できます。加えて、カラムにイ
ンデクスが設定されていれば、データベースによっては LIKE クエリであっ
てもインデクスを使ったクエリを実行できるという利点があります。
=大小文字を区別しない厳密一致です。例えば、 search_fields を
['=first_name', '=last_name'] にして、ユーザが john lennon を検
索した場合、 Django は以下のような WHERE 節の SQL に等価な検索を実行
します:
WHERE (first_name ILIKE 'john' OR last_name ILIKE 'john')
AND (first_name ILIKE 'lennon' OR last_name ILIKE 'lennon')
クエリ入力はスペース区切りなので、この例に従うと、 first_name が
'john winston' である (スペースを含む) ようなレコードは検索でき
ないので注意してください。
@- 全文検索マッチを実行します。デフォルトの search メソッドに似ていますが、
インデクスを使います。現在のところ MySQL でしか使えません。
-
ModelAdmin.formfield_overrides
This provides a quick-and-dirty way to override some of the
Field options for use in the admin.
formfield_overrides is a dictionary mapping a field class to a dict of
arguments to pass to the field at construction time.
Since that’s a bit abstract, let’s look at a concrete example. The most common
use of formfield_overrides is to add a custom widget for a certain type of
field. So, imagine we’ve written a RichTextEditorWidget that we’d like to
use for large text fields instead of the default <textarea>. Here’s how we’d
do that:
from django.db import models
from django.contrib import admin
# Import our custom widget and our model from where they're defined
from myapp.widgets import RichTextEditorWidget
from myapp.models import MyModel
class MyModelAdmin(admin.ModelAdmin):
formfield_overrides = {
models.TextField: {'widget': RichTextEditorWidget},
}
Note that the key in the dictionary is the actual field class, not a string.
The value is another dictionary; these arguments will be passed to
__init__(). See フォーム API for details.
Warning
If you want to use a custom widget with a relation field (i.e.
ForeignKey or
ManyToManyField), make sure you haven’t included
that field’s name in raw_id_fields or radio_fields.
formfield_overrides won’t let you change the widget on relation fields
that have raw_id_fields or radio_fields set. That’s because
raw_id_fields and radio_fields imply custom widgets of their own.
-
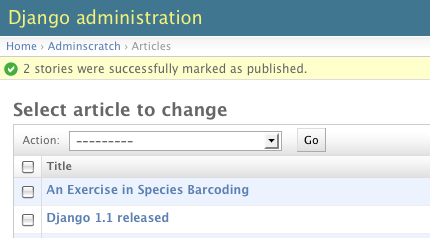
ModelAdmin.actions
A list of actions to make available on the change list page. See
Admin actions for details.
-
ModelAdmin.actions_on_top
-
ModelAdmin.actions_on_bottom
Controls where on the page the actions bar appears. By default, the admin
changelist displays actions at the top of the page (actions_on_top = True;
actions_on_bottom = False).
-
ModelAdmin.change_list_template
Path to a custom template that will be used by the model objects “change list”
view. Templates can override or extend base admin templates as described in
Overriding Admin Templates.
If you don’t specify this attribute, a default template shipped with Django
that provides the standard appearance is used.
-
ModelAdmin.change_form_template
Path to a custom template that will be used by both the model object creation
and change views. Templates can override or extend base admin templates as
described in Overriding Admin Templates.
If you don’t specify this attribute, a default template shipped with Django
that provides the standard appearance is used.
-
ModelAdmin.object_history_template
Path to a custom template that will be used by the model object change history
display view. Templates can override or extend base admin templates as
described in Overriding Admin Templates.
If you don’t specify this attribute, a default template shipped with Django
that provides the standard appearance is used.
-
ModelAdmin.delete_confirmation_template
Path to a custom template that will be used by the view responsible of showing
the confirmation page when the user decides to delete one or more model
objects. Templates can override or extend base admin templates as described in
Overriding Admin Templates.
If you don’t specify this attribute, a default template shipped with Django
that provides the standard appearance is used.
ModelAdmin のメソッド
-
ModelAdmin.save_model(self, request, obj, form, change)
save_model メソッドは HttpRequest, モデルインスタンス、
ModelForm インスタンス、オブジェクトの追加か変更かを表すブール値 (変更
の場合には True) を引数にとります。このメソッドを使えば、オブジェクトの
保存前 (pre-save) および保存後 (post-save) 処理を実行できます。
保存前に request.user をオブジェクトに保存するには、以下のようにします:
class ArticleAdmin(admin.ModelAdmin):
def save_model(self, request, obj, form, change):
obj.user = request.user
obj.save()
-
ModelAdmin.save_formset(self, request, form, formset, change)
save_formset メソッドは HttpRequest, モデルインスタンス、親クラスの
ModelForm インスタンス、オブジェクトの追加か変更かを表すブール値 (変更
の場合には True) を引数にとります。
フォームセットの各モデルインスタンスの保存前に request.user をオブジェ
クトに保存するには、以下のようにします:
class ArticleAdmin(admin.ModelAdmin):
def save_formset(self, request, form, formset, change):
instances = formset.save(commit=False)
for instance in instances:
instance.user = request.user
instance.save()
formset.save_m2m()
-
ModelAdmin.get_urls(self)
The get_urls method on a ModelAdmin returns the URLs to be used for
that ModelAdmin in the same way as a URLconf. Therefore you can extend them as
documented in URL ディスパッチャ:
class MyModelAdmin(admin.ModelAdmin):
def get_urls(self):
urls = super(MyModelAdmin, self).get_urls()
my_urls = patterns('',
(r'^my_view/$', self.my_view)
)
return my_urls + urls
Note
Notice that the custom patterns are included before the regular admin
URLs: the admin URL patterns are very permissive and will match nearly
anything, so you’ll usually want to prepend your custom URLs to the built-in
ones.
However, the self.my_view function registered above suffers from two
problems:
- It will not perform and permission checks, so it will be accessible to
the general public.
- It will not provide any header details to prevent caching. This means if
the page retrieves data from the database, and caching middleware is
active, the page could show outdated information.
Since this is usually not what you want, Django provides a convenience wrapper
to check permissions and mark the view as non-cacheable. This wrapper is
AdminSite.admin_view() (i.e. self.admin_site.admin_view inside a
ModelAdmin instance); use it like so:
class MyModelAdmin(admin.ModelAdmin):
def get_urls(self):
urls = super(MyModelAdmin, self).get_urls()
my_urls = patterns('',
(r'^my_view/$', self.admin_site.admin_view(self.my_view))
)
return my_urls + urls
Notice the wrapped view in the fifth line above:
(r'^my_view/$', self.admin_site.admin_view(self.my_view))
This wrapping will protect self.my_view from unauthorized access and will
apply the django.views.decorators.cache.never_cache decorator to make sure
it is not cached if the cache middleware is active.
If the page is cacheable, but you still want the permission check to be performed,
you can pass a cacheable=True argument to AdminSite.admin_view():
(r'^my_view/$', self.admin_site.admin_view(self.my_view, cacheable=True))
-
ModelAdmin.formfield_for_foreignkey(self, db_field, request, **kwargs)
The formfield_for_foreignkey method on a ModelAdmin allows you to
override the default formfield for a foreign key field. For example, to
return a subset of objects for this foreign key field based on the user:
class MyModelAdmin(admin.ModelAdmin):
def formfield_for_foreignkey(self, db_field, request, **kwargs):
if db_field.name == "car":
kwargs["queryset"] = Car.objects.filter(owner=request.user)
return db_field.formfield(**kwargs)
return super(MyModelAdmin, self).formfield_for_foreignkey(db_field, request, **kwargs)
This uses the HttpRequest instance to filter the Car foreign key field
to only the cars owned by the User instance.
Other methods
-
ModelAdmin.add_view(self, request, form_url='', extra_context=None)
Django view for the model instance addition page. See note below.
-
ModelAdmin.change_view(self, request, object_id, extra_context=None)
Django view for the model instance edition page. See note below.
-
ModelAdmin.changelist_view(self, request, extra_context=None)
Django view for the model instances change list/actions page. See note below.
-
ModelAdmin.delete_view(self, request, object_id, extra_context=None)
Django view for the model instance(s) deletion confirmation page. See note below.
-
ModelAdmin.history_view(self, request, object_id, extra_context=None)
Django view for the page that shows the modification history for a given model
instance.
Unlike the hook-type ModelAdmin methods detailed in the previous section,
these five methods are in reality designed to be invoked as Django views from
the admin application URL dispatching handler to render the pages that deal
with model instances CRUD operations. As a result, completely overriding these
methods will significantly change the behavior of the admin application.
One comon reason for overriding these methods is to augment the context data
that is provided to the template that renders the view. In the following
example, the change view is overridden so that the rendered template is
provided some extra mapping data that would not otherwise be available:
class MyModelAdmin(admin.ModelAdmin):
# A template for a very customized change view:
change_form_template = 'admin/myapp/extras/openstreetmap_change_form.html'
def get_osm_info(self):
# ...
def change_view(self, request, object_id, extra_context=None):
my_context = {
'osm_data': self.get_osm_info(),
}
return super(MyModelAdmin, self).change_view(request, object_id,
extra_context=my_context)