サービスの挙動¶
Docker Engine が swarm モードで 動作時、アプリケーションのイメージをデプロイするには、サービス(service)を作成します。通常、サービスとは、大きなアプリケーションを構成しているマイクロサービス用のイメージです。サービスの例としては、 HTTP サーバ、データベース、その他あらゆる種類の実行可能なプログラムを含み、必要があれば分散環境で実行します。
サービスの作成時、使用するコンテナイメージの指定と、コンテナ内で実行するコマンドの指定をします。また、サービスに対して以下のオプションを含む定義ができます。
- swarm を swarm の外からサービスを利用できるようにするポート
- swarm 内のサービスが、他のサービスと接続するためのオーバレイ・ネットワーク
- CPU とメモリの制限と予約
- ローリング・アップデートのポリシー(方針)
- swarm 内で実行するイメージのレプリカ数
サービス、タスク、コンテナ¶
swarm に対してサービスをデプロイ時、 swarm manager はサービスに対する定義を期待状態(desired state)として受け取ります。そして、1つまたは複数のレプリカ・タスクを、 サービスとして swarm 上のノードにスケジュールします。タスクは swarm 上にあるノード上でお互い独立して稼働します。
たとえば、 HTTP リスナーが3つあるインスタンス(実体)間での負荷分散を想定します。下図は HTTP リスナー・サービスとして3つのレプリカがあります。リスナーの3つの実体とは、swarm 上における個々のタスクです。
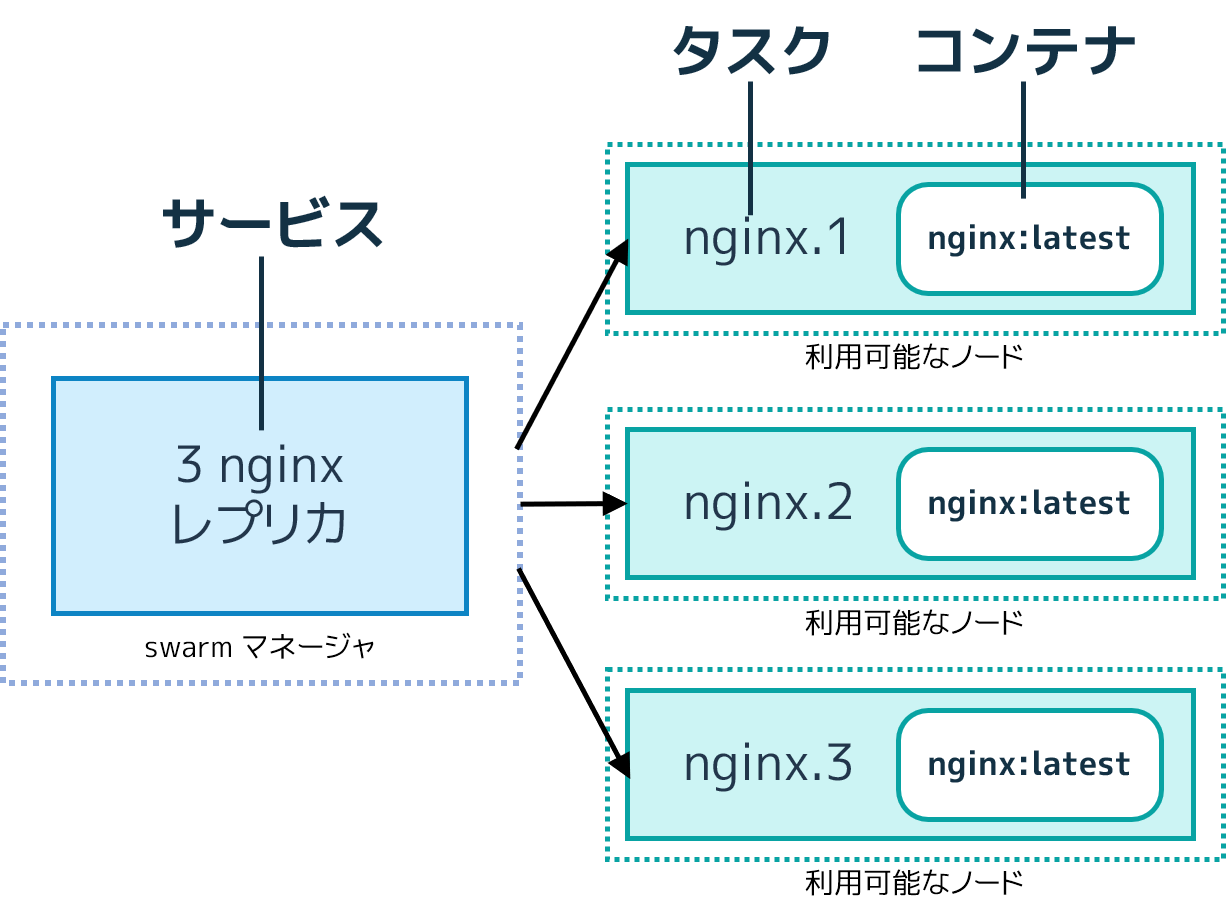
コンテナとは隔離されたプロセス(isolated process)です。swarm モードのモデル上では、各タスクは正確に1つのコンテナを呼び出し(invokeし)ます。タスクはコンテナをスケジュールして配置する「スロット(slot)」と似ています。コンテナが稼働したら、スケジューラはタスクが実行中の状態であると認識します。もしもコンテナのヘルスチェックで障害が発生するか終了すると、タスクは終了(terminate)とみなします。
タスクとスケジューリング¶
タスクとは、swarm においてスケジュールをする最小単位です。サービスの作成や更新によって、期待するサービス状態を宣言するとき、オーケストレータによってスケジューリングするタスクの期待状態(desired state)を認識します。たとえば、オーケストレータは常時 HTTP リスナーを3つ実行し続けなさい、といった命令のサービスを定義できます。オーケストレータは3つのタスクを作成をする反応をします。それぞれのタスクはスロットであり、スケジューラはスロットが起動したコンテナで埋まる(満たされる)ようにします。つまり、タスクを実体化(インスタンス化)したものがコンテナです。もしも HTTP リスナーのタスクが、ヘルスチェックやクラッシュによる障害が起こると、オーケストレータは新しいレプリカタスクを作成、つまり、新しいコンテナを作成します。
タスクとは一方通行の仕組みです。タスクは、割り当て、準備、実行など一連の状態を順々に進行します。もしもタスクで障害が起こると、オーケストレータはタスクとそのコンテナを削除します。それから、サービスを定義する期待状態(desired state)に従って、新しいタスクを作成し、置き換えます。
Docker swarm モードの根底となる仕組み(ロジック)は、一般的なスケジューラとオーケストレータを目的としています。コンテナを意識しなくてもいいように、サービスとタスクで抽象化するような実装をしています。仮定ではありますが、仮想マシンのタスクや、コンテナ化していないプロセスのタスクの実装もできるでしょう。スケジューラとオーケストレータは、タスクがどのような種類なのかを認識しません。しかしながら、Docker の現行バージョンのみがコンテナ・タスクをサポートしています。
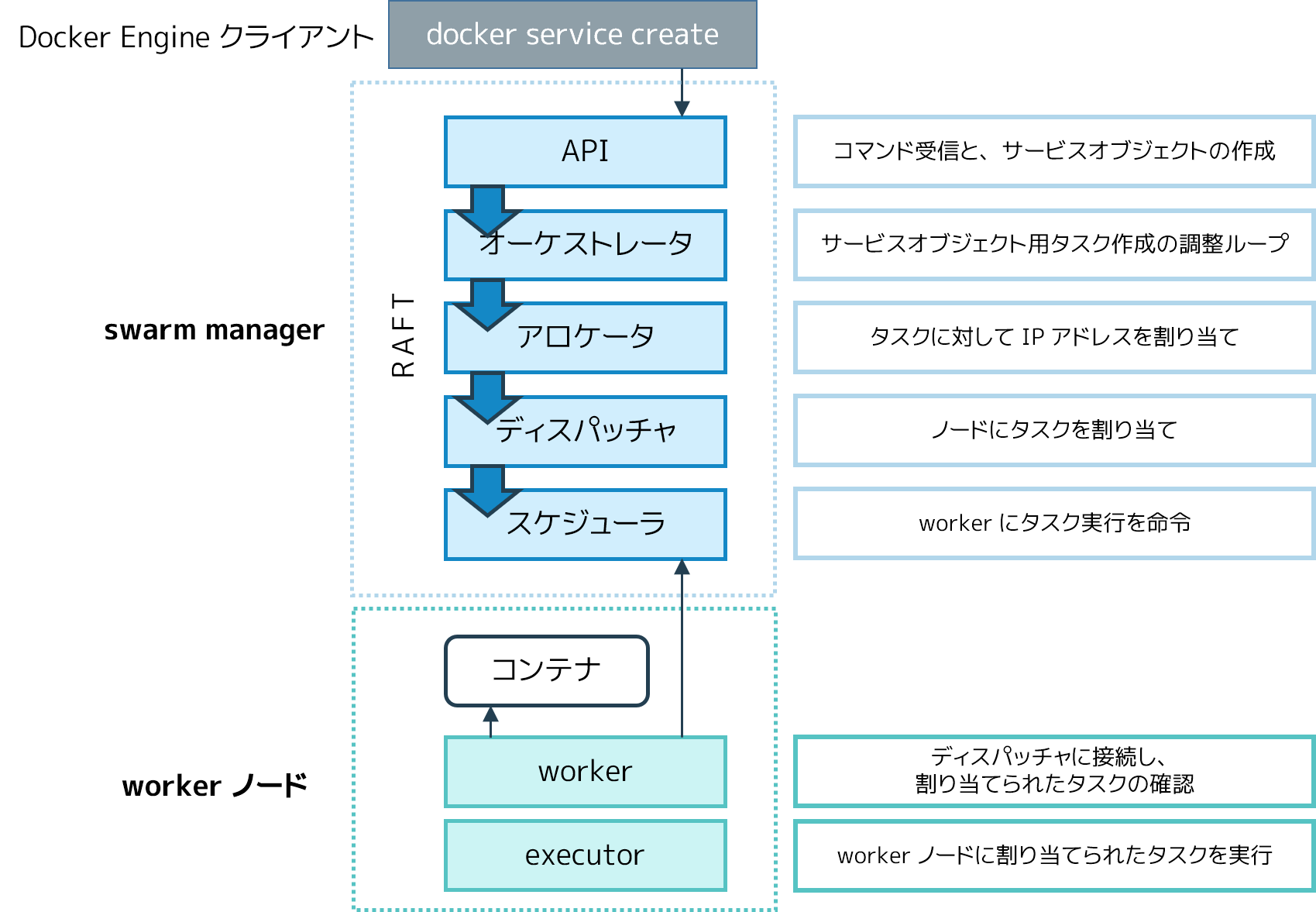
下図は、どのようにして swarm mode がサービス作成要求を受け取り、worker ノードに対してタスクをスケジュールするかを説明します。
サービスの保留(pending)¶
サービスを設定したくても、その時点では swarm 上でタスクを実行するノードがない状態もあるでしょう。その場合、サービスの状態は penging になります。サービスが pending 状態が続いてしまう、いくつかのケースを取り上げます。
注釈
目的がデプロイ済みのサービスを抑制したいだけであれば、ここで挙げる pending 状態にする方法を試みるかわりに、サービスを 0 にスケールします。
- サービス作成を試みる時、全てのノードが一次停止もしくはドレイン状態であれば、ノードが利用可能になるまで待機中(pending)になります。ところが、1つめのノードが利用可能になれば、全てのタスク実行をその段階で試みます。そのため、プロダクション環境では望ましくありません。
- サービスに対してメモリ使用量の予約が可能です。必要なメモリを割り当て可能なノードが swarm になければ、サービスがタスクを実行可能なノードが利用可能になるまで待機中になります。もしも 500GB のような非常に大きなメモリを指定した場合は、本当に要件を満たすノードが現れるまで、タスクは永久に待機中のままになります。
- サービスを実行する場所に制約(constraint)をつけられます。しかし、場合によっては制約を適用できない可能性があります。
この挙動について説明すると、タスクの要件と設定は、その時点における swarm の状態と強く結びつきません。あなたが swarm の管理者であれば、 swarm に対して期待する状態を宣言すると、 manager が swarm 内の node において、その状態になるような動作を始めます。あなたが swarm 上のタスクについて細かく管理する必要はありません
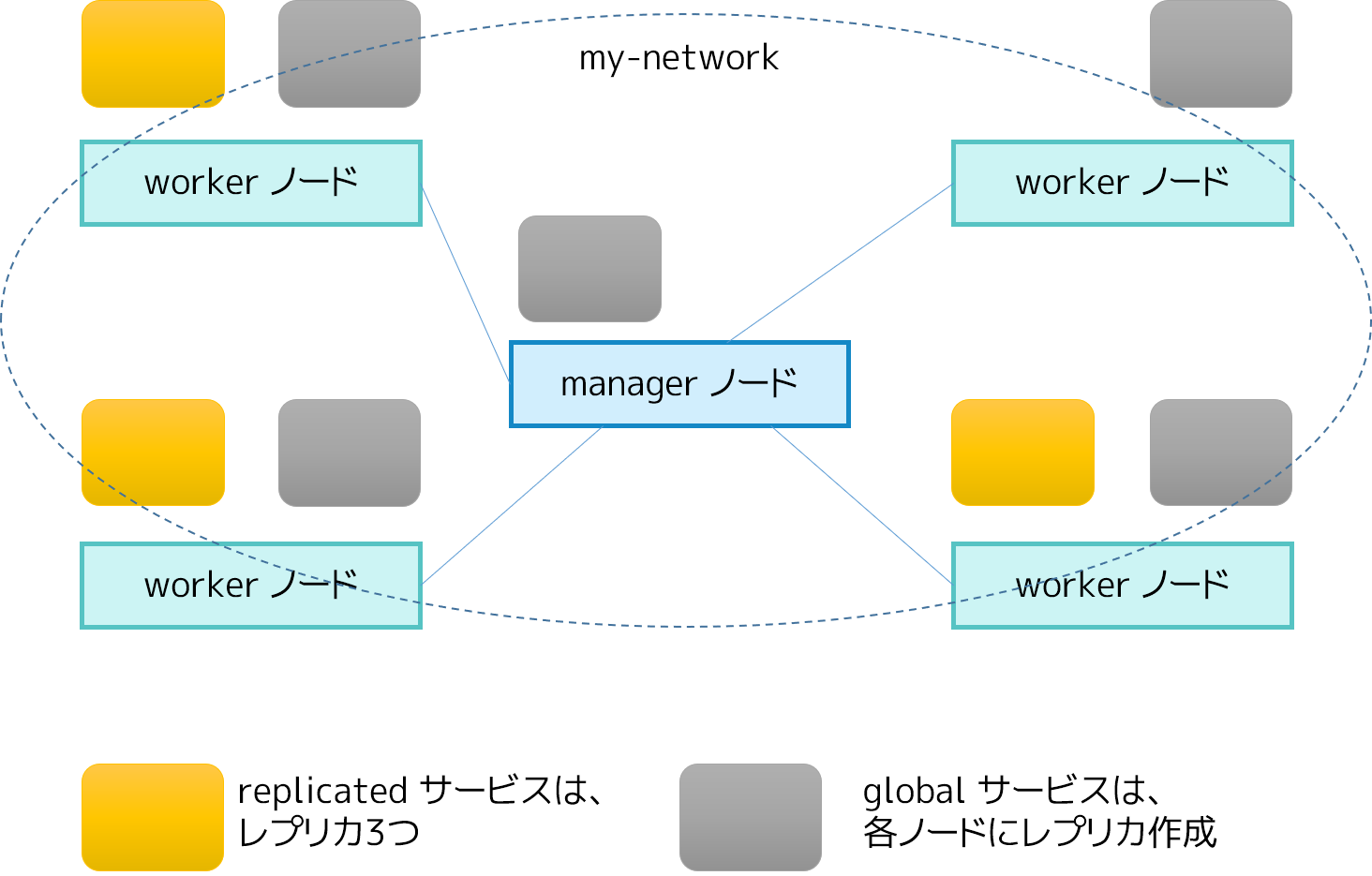
複製とグローバル・サービス¶
サービスのデプロイ形式(deployment)は、複製(replicated)とグローバル(global)の2種類です。
複製サービス(replicated service)とは、実行したいタスクに対して個々の数を指定します。たとえば、3つのレプリカを持つ HTTP サービスをデプロイすると決めると、各レプリカは同じ内容で稼働します。
グローバル・サービス(global service)とは、全ノード上でそれぞれ1つのタスクを実行します。タスクの数を事前に指定する必要はありません。swarm に対してノードを追加する度に、オーケストレータはタスクを作成し、スケジューラはこの新しいノードにタスクを割り当てます。グローバル・サービスが適しているのは監視用エージェント、アンチウイルス・スキャナー、その他のタイプのコンテナなど、swarm の各ノード上で実行させたいものです。
下図では、3つのサービス複製が黄色で、グローバル・サービスが灰色です。
さらに学ぶ¶
参考
- How services work
- https://docs.docker.com/engine/swarm/how-swarm-mode-works/services/