BLACKHOLE ストレージエンジンは、データを受け取るけれども破棄して格納しない「ブラックホール」として機能します。 検索は、常に空の結果を返します。
mysql> CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO test VALUES(1,'record one'),(2,'record two');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM test;
Empty set (0.00 sec)
ソースから MySQL を構築する場合に BLACKHOLE ストレージエンジンを有効にするには、CMake を -DWITH_BLACKHOLE_STORAGE_ENGINE オプションで呼び出します。
BLACKHOLE エンジンのソースを調べるには、MySQL ソース配布の sql ディレクトリを検索します。
BLACKHOLE テーブルを作成すると、サーバーはグローバルデータディクショナリにテーブル定義を作成します。 テーブルに関連付けられたファイルがありません。
BLACKHOLE ストレージエンジンはすべての種類のインデックスをサポートしています。 すなわち、テーブル定義にインデックス宣言を含めることができます。
BLACKHOLE ストレージエンジンはパーティション分割をサポートしていません。
BLACKHOLE ストレージエンジンが SHOW ENGINES ステートメントで使用できるかどうかを確認できます。
BLACKHOLE テーブルへの挿入にはデータは格納されませんが、ステートメントベースのバイナリロギングが有効になっている場合は、SQL ステートメントがログに記録され、複製サーバーに複製されます。 これは、繰り返しまたはフィルタメカニズムとして役立つ場合があります。
アプリケーションでレプリカ側のフィルタリングルールが必要だが、最初にすべてのバイナリログデータをレプリカに転送すると、トラフィックが多すぎるとします。 このような場合は、レプリケーションソースサーバー上で、デフォルトのストレージエンジンが BLACKHOLE である「「ダミー」」レプリカプロセスを次のように設定できます:
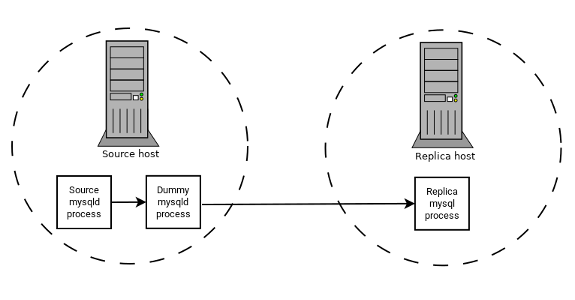
ソースはバイナリログに書き込みます。 「「ダミー」」 mysqld プロセスはレプリカとして機能し、replicate-do-* ルールと replicate-ignore-* ルールの目的の組合せを適用して、独自のフィルタ処理された新しいバイナリログを書き込みます。 セクション17.1.6「レプリケーションおよびバイナリロギングのオプションと変数」を参照してください。 このフィルタ処理されたログはレプリカに提供されます。
ダミープロセスは実際にはデータを格納しないため、レプリケーションソースサーバーで追加の mysqld プロセスを実行することで発生する処理オーバーヘッドはほとんどありません。 このタイプの設定は、追加のレプリカを使用して繰り返すことができます。
BLACKHOLE テーブルの INSERT トリガーは期待どおりに機能します。 しかし、実際には BLACKHOLE テーブルはデータを格納しないため、UPDATE および DELETE トリガーは有効ではありません。トリガー定義の FOR EACH ROW 句は、行がないために適用されません。
BLACKHOLE ストレージエンジンのその他の利用方法は、次のとおりです。
ダンプファイル構文の検証。
バイナリロギングのオーバーヘッドを測定 (バイナリロギングが有効である場合と有効でない場合のパフォーマンスを
BLACKHOLEを利用して比較することで)。BLACKHOLEは本質的には 「no-op」ストレージエンジンであるため、ストレージエンジン自体には関係ないパフォーマンスボトルネックの検出に使用される場合があります。
コミットされたトランザクションはバイナリログに書き込まれ、ロールバックされたトランザクションは書き込まれないという意味で、BLACKHOLE エンジンはトランザクション対応です。
Blackhole エンジンと自動インクリメントカラム
BLACKHOLE エンジンは no-op エンジンです。 BLACKHOLE を使用してテーブルに対して実行される操作は影響を受けません。 これは、自動増分される主キーカラムの動作を考慮する際に注意する必要があります。 エンジンはフィールド値を自動的に増分せず、自動増分フィールドの状態を保持しません。 これは、レプリケーションで重要な意味を持ちます。
次の 3 つの条件がすべて適用される次のレプリケーションシナリオを検討します。
ソースサーバーには、主キーである自動増分フィールドを持つブラックホールテーブルがあります。
レプリカには同じテーブルが存在しますが、MyISAM エンジンを使用します。
ソーステーブルへの挿入は、
INSERTステートメント自体で自動増分値を明示的に設定せずに、またはSET INSERT_IDステートメントを使用して実行されます。
このシナリオでは、主キーカラムで重複エントリエラーが発生してレプリケーションが失敗します。
ステートメントベースのレプリケーションでは、コンテキストイベントの INSERT_ID の値は常に同じです。 したがって、主キーカラムの値が重複する行を挿入しようとすると、レプリケーションは失敗します。
行ベースのレプリケーションでは、エンジンが戻す行の値は、各挿入で常に同じです。 この結果、レプリカは主キーカラムに同じ値を使用して 2 つの挿入ログエントリをリプレイしようとするため、レプリケーションは失敗します。
カラムのフィルタリング
行ベースのレプリケーション (binlog_format=ROW) を使用する場合、セクション17.5.1.9「ソースとレプリカで異なるテーブル定義を使用したレプリケーション」 のセクションで説明されているように、最後のカラムがテーブルから欠落しているレプリカがサポートされます。
このフィルタリングはレプリカ側で機能します。つまり、カラムはフィルタで除外される前にレプリカにコピーされます。 カラムをレプリカにコピーすることは望ましくないケースが 2 つ以上あります:
データが機密である場合、レプリカサーバーはそのデータにアクセスできません。
ソースに多数のレプリカがある場合、レプリカに送信する前にフィルタリングすると、ネットワークトラフィックが削減される可能性があります。
ソースカラムのフィルタリングは、BLACKHOLE エンジンを使用して実行できます。 これは、ソーステーブルのフィルタリングの実現方法と同様の方法で実行されます - BLACKHOLE エンジンおよび --replicate-do-table または --replicate-ignore-table オプションを使用します。
ソースの設定は次のとおりです:
CREATE TABLE t1 (public_col_1, ..., public_col_N,
secret_col_1, ..., secret_col_M) ENGINE=MyISAM;信頼できるレプリカの設定は次のとおりです:
CREATE TABLE t1 (public_col_1, ..., public_col_N) ENGINE=BLACKHOLE;信頼できないレプリカの設定は次のとおりです:
CREATE TABLE t1 (public_col_1, ..., public_col_N) ENGINE=MyISAM;