ソースに接続するレプリカの数が増えるにつれて、各レプリカがソースへのクライアント接続を使用するため、負荷も最小限に抑えられます。 また、各レプリカはソースバイナリログの完全なコピーを受信する必要があるため、ソースのネットワーク負荷も増加し、ボトルネックが発生する可能性があります。
あるソースに接続されている多数のレプリカを使用しており、そのソースがリクエストの処理にもビジー状態である場合 (たとえば、スケールアウトソリューションの一部として)、レプリケーションプロセスのパフォーマンスを向上させることが必要な場合があります。
レプリケーションプロセスのパフォーマンスを向上させる方法の 1 つは、ソースを 1 つのレプリカにのみレプリケートし、残りのレプリカが個々のレプリケーション要件のためにこのプライマリレプリカに接続できるようにする、より深いレプリケーション構造を作成することです。 この構造のサンプルを図17.3「追加のレプリケーションソースを使用したパフォーマンスの向上」に示します。
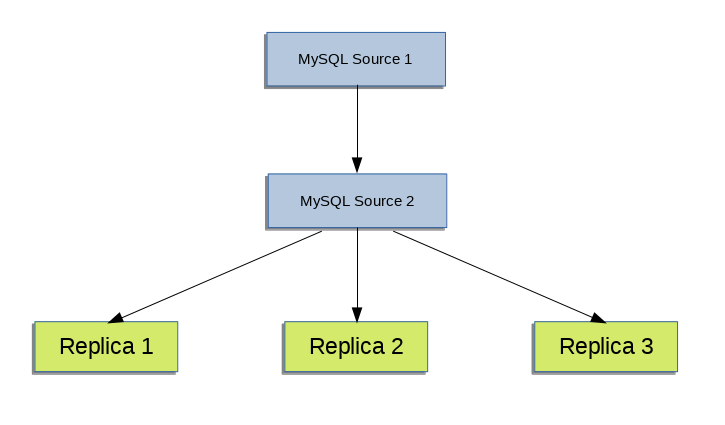
これが機能するには、MySQL インスタンスを次のように構成する必要があります。
ソース 1 は、すべての変更および更新がデータベースに書き込まれるプライマリソースです。 バイナリロギングは、両方のソースサーバー (デフォルト) で有効になっています。
ソース 2 はサーバー Source 1 へのレプリカで、レプリケーション構造内の残りのレプリカにレプリケーション機能を提供します。 ソース 2 は、ソース 1 への接続が許可されている唯一のマシンです。 ソース 2 では、
--log-slave-updatesオプションが有効 (デフォルト) になっています。 このオプションを使用すると、ソース 1 からのレプリケーション命令もソース 2 のバイナリログに書き込まれるため、それらを実際のレプリカにレプリケートできます。レプリカ 1、レプリカ 2 およびレプリカ 3 はレプリカとしてソース 2 に機能し、ソース 2 からの情報をレプリケートします。この情報は、実際にはソース 1 に記録されたアップグレードで構成されます。
前述のソリューションを直接データベースソリューションとして使用すると、プライマリソースでのクライアントの負荷とネットワークインタフェースの負荷が軽減されるため、プライマリソースの全体的なパフォーマンスが向上します。
レプリカがソースでのレプリケーションプロセスの維持に問題がある場合は、いくつかのオプションを使用できます:
可能であれば、リレーログとデータファイルを異なる物理ドライブに置きます。 これを行うには、
relay_logシステム変数を設定してリレーログの場所を指定します。バイナリログファイルおよびリレーログファイルの読み取りに対するディスク I/O アクティビティーが大きい場合は、
rpl_read_sizeシステム変数の値を増やすことを検討してください。 このシステム変数は、ログファイルから読み取られるデータの最小量を制御し、それを増やすと、ファイルデータがオペレーティングシステムによって現在キャッシュされていない場合にファイルの読取りおよび I/O の停止が減少する可能性があります。 バイナリログおよびリレーログファイルから読み取るスレッドごとに、この値のバッファーが割り当てられます。これには、ソース上のダンプスレッドやレプリカ上のコーディネータスレッドも含まれます。 したがって、大きな値を設定すると、サーバーのメモリー消費に影響する可能性があります。レプリカがソースより大幅に低速な場合は、異なるデータベースを異なるレプリカにレプリケートする責任を分けることが必要になる場合があります。 セクション17.4.6「異なるレプリカへの異なるデータベースのレプリケート」を参照してください。
ソースでトランザクションを使用していて、レプリカでのトランザクションサポートに関心がない場合は、レプリカで
MyISAMまたは別の非トランザクションエンジンを使用します。 セクション17.4.4「異なるソースおよびレプリカのストレージエンジンでのレプリケーションの使用」を参照してください。レプリカがソースとして機能せず、障害発生時にソースを起動できるようにするための潜在的なソリューションがある場合は、レプリカの
log_slave_updatesシステム変数を無効にできます。 これにより、「dumb」 レプリカは、実行したイベントを独自のバイナリログに記録することもできなくなります。