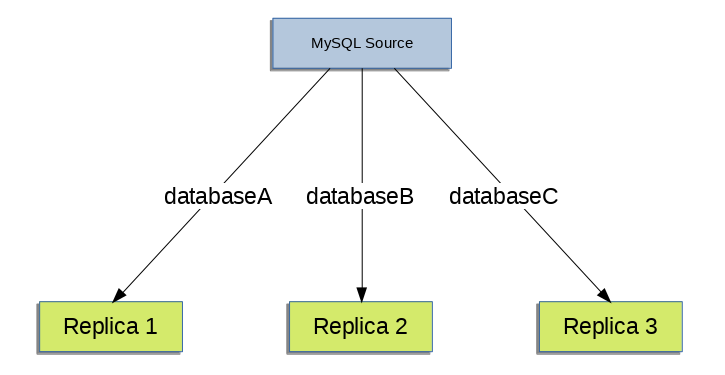
単一のソースサーバーがあり、異なるデータベースを異なるレプリカにレプリケートする必要がある場合があります。 たとえば、データ分析時の負荷を分散するために、異なる売上データを異なる部門に分散したい場合です。 このレイアウトの例を図17.2「個別のレプリカへのデータベースのレプリケート」に示します。
この分離を実現するには、ソースとレプリカを通常どおりに構成し、各レプリカで --replicate-wild-do-table 構成オプションを使用して、各レプリカが処理するバイナリログステートメントを制限します。
ステートメントベースレプリケーションを使用する場合は、--replicate-do-db をこの目的に使用しないでください。ステートメントベースレプリケーションを使用すると、このオプションの影響は現在選択されているデータベースによって異なります。 このことは、混合形式のレプリケーションにも当てはまります。一部の更新をステートメントベース形式を使用して複製できるためです。
しかし、行ベースレプリケーションだけを使用している場合には、この目的のために --replicate-do-db を使用しても安全なはずです。この場合には、現在選択されているデータベースがオプションの動作に影響しないためです。
たとえば、図17.2「個別のレプリカへのデータベースのレプリケート」 に示されている分離をサポートするには、START REPLICA | SLAVE を実行する前に、各レプリカを次のように構成する必要があります:
レプリカ 1 では
--replicate-wild-do-table=databaseA.%を使用する必要があります。レプリカ 2 では
--replicate-wild-do-table=databaseB.%を使用する必要があります。レプリカ 3 では
--replicate-wild-do-table=databaseC.%を使用する必要があります。
この構成内の各レプリカは、ソースからバイナリログ全体を受け取りますが、そのレプリカで有効な --replicate-wild-do-table オプションに含まれるデータベースとテーブルに適用されるバイナリログからのイベントのみを実行します。
レプリケーションを開始する前にレプリカに同期する必要があるデータがある場合は、次のようないくつかの選択肢があります:
すべてのデータを各レプリカに同期し、保持しないデータベースまたはテーブル、あるいはその両方を削除します。
mysqldump を使用して、データベースごとに個別のダンプファイルを作成し、各レプリカに適切なダンプファイルをロードします。
-
RAW データファイルダンプを使用し、各レプリカに必要な特定のファイルおよびデータベースのみを含めます。
注記これは、
innodb_file_per_tableを使用しないかぎり、InnoDBデータベースでは機能しません。