NDB Cluster は、2 つのクラスタ間の双方向レプリケーションや、任意の数のクラスタ間の循環レプリケーションに使用できます。
循環レプリケーションの例. 次のいくつかの段落では、クラスタ 1 がクラスタ 2 のレプリケーションソースとして機能し、クラスタ 3 がクラスタ 1 のソースとして機能する 3 つの NDB Cluster 番号 1、2、および 3 を含むレプリケーション設定の例を検討します。 各クラスタは 2 つの SQL ノードを持ち、SQL ノード A と B はクラスタ 1 に属し、SQL ノード C と D はクラスタ 2 に属し、SQL ノード E と F はクラスタ 3 に属しています。
これらのクラスタを使用する循環レプリケーションは、次の条件を満たすかぎり、サポートされます。
すべてのソースおよびレプリカの SQL ノードが同じです。
ソースおよびレプリカとして機能するすべての SQL ノードは、
log_slave_updatesシステム変数を有効にして起動されます。
このタイプの循環レプリケーションのセットアップは、次の図に示すとおりです。
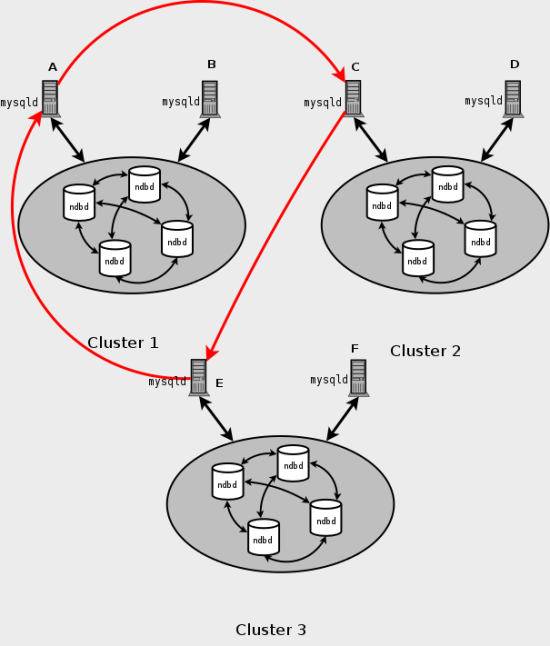
このシナリオでは、クラスタ 1 の SQL ノード A はクラスタ 2 の SQL ノード C に複製し、SQL ノード C はクラスタ 3 の SQL ノード E に複製し、SQL ノード E は SQL ノード A に複製します。 つまり、レプリケーションソースおよびレプリカとして使用されるすべての SQL ノードは、レプリケーション線 (図の曲線の矢印で示されています) によって直接接続されます。
次に示すように、すべてのソース SQL ノードがレプリカであるわけではないような方法で循環レプリケーションを設定することもできます:
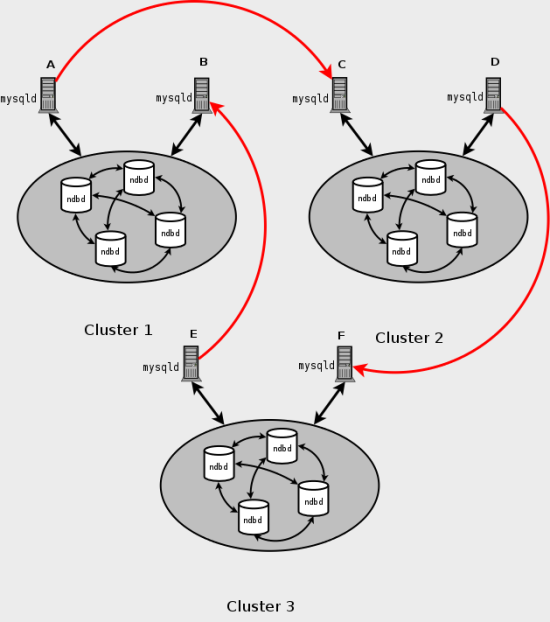
この場合、各クラスタ内の異なる SQL ノードがレプリケーションソースおよびレプリカとして使用されます。 log_slave_updates システム変数を有効にして SQL ノードを起動しないでください。 NDB Cluster のこのタイプの循環レプリケーションスキームでは、レプリケーションの行 (図の曲線矢印で再度示されています) が不連続である可能性がありますが、まだ徹底的にテストされていないため、実験的とみなす必要があることに注意してください。
NDB ネイティブのバックアップおよびリストアを使用したレプリカクラスタの初期化.
循環レプリケーションを設定する場合、ある NDB Cluster で管理クライアントの START BACKUP コマンドを使用してバックアップを作成し、ndb_restore を使用してこのバックアップを別の NDB Cluster に適用することによって、レプリカクラスタを初期化できます。 これにより、レプリカとして機能する 2 つ目の NDB Cluster SQL ノードにバイナリログが自動的に作成されることはありません。バイナリログを作成するには、その SQL ノードで SHOW TABLES ステートメントを発行する必要があります。これは、START REPLICA | SLAVE を実行する前に行う必要があります。 これは既知の問題です。
マルチソースフェイルオーバーの例. このセクションでは、サーバー ID 1、2、および 3 を持つ 3 つの NDB Cluster を持つマルチソース NDB Cluster レプリケーション設定でのフェイルオーバーについて説明します。 このシナリオでは、クラスタ 1 はクラスタ 2 および 3 に複製し、クラスタ 2 もクラスタ 3 に複製します。 この関係はここで示すとおりです。
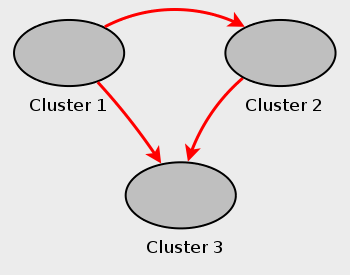
つまり、データはクラスタ 1 からクラスタ 3 へ異なる 2 つのルートを介して (直接、およびクラスタ 2 経由で) 複製されます。
マルチソースレプリケーションに関与するすべての MySQL サーバーがソースとレプリカの両方として動作するわけではなく、特定の NDB Cluster がレプリケーションチャネルごとに異なる SQL ノードを使用する可能性があります。 このようなケースを次に示します。
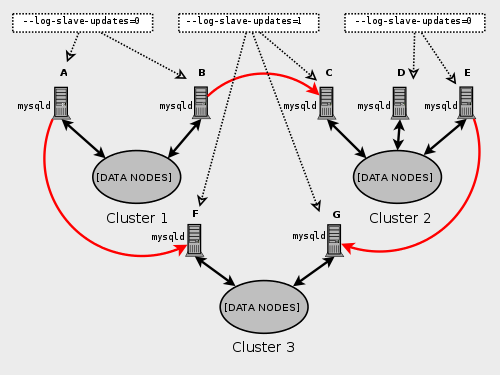
レプリカとして機能する MySQL サーバーは、log_slave_updates システム変数を有効にして実行する必要があります。 また、どの mysqld プロセスでこのオプションが必要か、前の図に示されています。
log_slave_updates システム変数を使用しても、レプリカとして実行されていないサーバーには影響しません。
複製しているクラスタの 1 つが停止した場合、フェイルオーバーの必要性が生じます。 この例では、クラスタ 1 のサービスが失われ、そのためにクラスタ 3 がクラスタ 1 の更新の 2 つのソースを失うケースを検討します。 NDB Cluster 間のレプリケーションは非同期であるため、クラスタ 1 から直接発生したクラスタ 3 の更新が、クラスタ 2 を介して受信した更新よりも新しいことは保証されません。 クラスタ 1 からの更新に関して、クラスタ 3 が確実にクラスタ 2 に追いつくことで、これに対処できます。 すなわち、MySQL サーバーに関して、未処理の更新を MySQL サーバー C からサーバー F に複製する必要があります。
サーバー C で、次のクエリーを実行します。
mysqlC> SELECT @latest:=MAX(epoch)
-> FROM mysql.ndb_apply_status
-> WHERE server_id=1;
mysqlC> SELECT
-> @file:=SUBSTRING_INDEX(File, '/', -1),
-> @pos:=Position
-> FROM mysql.ndb_binlog_index
-> WHERE orig_epoch >= @latest
-> AND orig_server_id = 1
-> ORDER BY epoch ASC LIMIT 1;
適切なインデックスを ndb_binlog_index テーブルに追加することで、このクエリーのパフォーマンスを向上できるため、フェイルオーバー時間が大幅に短縮される可能性があります。 詳細については、セクション23.6.4「NDB Cluster レプリケーションスキーマおよびテーブル」を参照してください。
@file および @pos の値を手動でサーバー C からサーバー F にコピーをします (またはアプリケーションで同様に実行させます)。 次に、サーバー F で、次の CHANGE REPLICATION SOURCE TO ステートメント (MySQL 8.0.23 の場合) または CHANGE MASTER TO ステートメント (MySQL 8.0.23 の場合) を実行します:
mysqlF> CHANGE MASTER TO
-> MASTER_HOST = 'serverC'
-> MASTER_LOG_FILE='@file',
-> MASTER_LOG_POS=@pos;
Or from MySQL 8.0.23:
mysqlF> CHANGE REPLICATION SOURCE TO
-> SOURCE_HOST = 'serverC'
-> SOURCE_LOG_FILE='@file',
-> SOURCE_LOG_POS=@pos;
これが完了したら、MySQL サーバー F で START REPLICA | SLAVE ステートメントを発行できます。これにより、サーバー B から発生した欠落している更新がサーバー F にレプリケートされます。
CHANGE REPLICATION SOURCE TO | CHANGE MASTER TO ステートメントは、サーバー ID のコンマ区切りリストを使用し、対応するサーバーから発生したイベントを無視する IGNORE_SERVER_IDS オプションもサポートしています。 詳細については、セクション13.4.2.1「CHANGE MASTER TO ステートメント」およびセクション13.7.7.36「SHOW SLAVE | REPLICA STATUS ステートメント」を参照してください。 このオプションと ndb_log_apply_status 変数との相互作用の詳細は、セクション23.6.8「NDB Cluster レプリケーションによるフェイルオーバーの実装」 を参照してください。